
Python
初见Python
1 | print()的使用 |
结果为False的类型
分支循环
if语句
1 | ''' |
while语句
1 | while 3<4: |
for语句
1 | #for 变量 in 可迭代对象: |
列表
1 |
|
列表的方法
增
1 | heros=['钢铁侠','绿巨人'] |
删
1 | remove() |
改
1 | heros[4]='钢铁侠' |
查
1 | nums.count() |
列表的运算
1 | s=[1,2,3] |
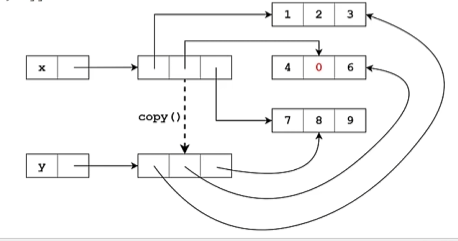
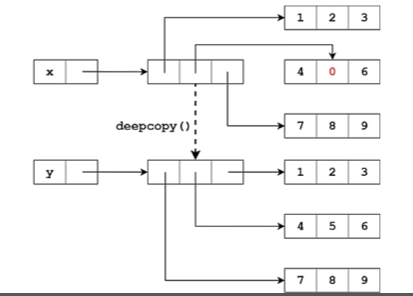
浅拷贝和深拷贝
1 | #浅拷贝 |
列表的推导式
1 | oho=[1,2,3,4] |
元组
1 | rhyme = (1,2,3,4,5,6,'你好') |
字符串
1 | #判断回文数 |
大小写字母变化函数
1 | x='I love china' |
左中右对齐函数
1 | x='有内鬼,停止交易!' |
查找函数
1 | #count(sub[,start[,end]]) |
替换函数
1 | #expandtabs([tabsize=8])将tab改为空格,返回新的字符串 |
判断和检测
1 | #返回布尔类型的值 |
截取字符串
1 | #区域删除字符串 |
格式化字符串
1 | year = 2004 |
[align]
| 值 | 含义 |
|---|---|
| ‘<’ | 强制字符串在可用空间内左对齐(默认) |
| ‘>’ | 强制字符串在可用空间内右对齐 |
| ‘=’ | 强制将填充放置在符号(如果有)之后但在数字之前的位置(这适用于以“+000000120”的形式打印字符串 |
| ‘^’ | 强制字符串在可用空间内居中 |
[sign]
| 值 | 含义 |
|---|---|
| ‘+’ | 正数前面填正号,负数前面填负号 |
| ‘-‘ | 只在负数前面添加负号 |
| ‘空格’ | 正数前面添加空格,负数前面添负号 |
[.precision] 精度
- 对于[type]设置为’f’或’F’的浮点数来说,是限定小数点后显示多少个数位
- 对于[type]设置为’g’或’G’的浮点数来说,是限定小数点前后一共显示多少个数位
- 对于非数字类型来说,限定的是最大字段的大小
- 对于整数类型来说,则不允许使用[.precision]选项
[type] 决定了数据如何呈现
f-字符串
1 | year=2004 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Eureka的小屋!